IROS 2024
PICaSo: A Collaborative Robotics System for Inpainting on Physical Canvas using Marker and Eraser
PICaSo는 생성 이미지 워크플로를 화면 밖 실제 캔버스로 옮기는 방법을 탐구합니다. 이를 위해 협업 로보틱스, 자연어 프롬프트, 그리고 그리고 지우고 다시 그릴 수 있는 멀티툴 그리퍼를 결합합니다.
Shady Nasrat, Jae-Bong Yi, Minseong Jo, Seung-Joon Yi
목차
Introduction
Recent advancements in text-to-image technologies have led to a significant increase in digital content production. However, the integration of these technologies into creating art with robots is still at an early stage, primarily due to the substantial disparity between digital and real-world settings. One notable advancement is the inpainting process, where text-to-image models produce or reinterpret sections of an image based on textual input. PICaSo introduces a robotic system designed to support the inpainting process on a physical canvas, enabling multiple users to cooperate and improve their creative ideas using natural language shown in Fig. . This unique approach brings together human creativity and technological precision in visual art, allowing for collaborative brainstorming by adding or refining elements of the canvas. The potential benefits of a collaborative assistant in therapeutic art are evident[1], [2], [3], as it enables group drawing sessions that can enhance mental health and overall well-being. PICaSo’s collaborative inpainting process serves as a supportive partner, offering guidance throughout the artistic process involving multiple users, making it particularly beneficial for those who may have physical or skill-related limitations with drawing.

We prepared for the inpainting process by selecting the appropriate tools, such as a marker and an eraser, and using a whiteboard as our canvas. To enhance efficiency, we also designed a multi-gripper capable of holding markers, erasers, and a camera for added convenience. Our waypoint generation uses the pixel-to-pixel line extraction algorithm introduced in [4]. This algorithm efficiently extracts points and lines from an image while maintaining quality and reducing processing time. Although drawing proved straightforward, the challenge arose in clearing process. Prior to our method’s development, clearing was an unexplored territory, with no established techniques. Consequently, we innovated a new method to trace back drawn waypoints within a selected mask, enabling their removal from the canvas without impacting the surrounding artwork.
Since our waypoint generation algorithm is based on a morphological transformation for image skeletonization, it required the input image to adhere to a specific style that excludes bold lines, shading, or colors. The pre-trained text-to-image model faced challenges in creating images with this specific style, often resulting in a generic random cartoon styles where regular prompt tuning couldn’t yielding the desired outcome style. To address this issue the style gap between the text-to-image style and the pixel-to-pixel line extraction algorithm’s desired style needs to be minimized. This requires learning a new style that is better suited for precise drawing and inpainting.
To reduce the style gap between generated images and the line extraction algorithm, we propose a fine-tuned model, trained on a style in which it is efficient to extract lines from. First we collected our dataset from cartoon images, which were characterized by uniform black thin lines devoid of colors and shading. Both SDXL1.0 [5] and SDXL1.0-inpainting-0.1 models were fine-tuned on this dataset to understand the unique style and features of these images, enabling more accurate line extraction. In order to successfully complete the inpainting process, we selected the suitable tools for the task. Our chosen canvas was a whiteboard, and we utilized a marker as well as an eraser. To optimize our use of these tools, we developed a multi-gripper capable of holding markers, eraser and a camera for added convenience during the process.
We have outlined our primary contributions by introducing physical inpainting, a novel form of canvas manipulation necessary for collaborative drawing tasks involving humans and robots. We introduced clearing algorithm allowing editing canvas. Our system is designed to be scalable, enabling multiple users to work together on a single canvas. Additionally, we have presented a comprehensive approach to bridging the gap between pre-trained models and line extraction algorithms. Both the hardware and software code for PICaSo are available as open-source resources.
Related Work
Drawing Tools
Previous research papers addressing drawing robotics tasks have primarily focused on aspects such as trajectory planning, stroke generation, and optimization techniques to improve drawing accuracy, documented in [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16]. These techniques include the utilization of various tools such as pens [17], pencils [9], [13], [15], [16], markers [10], paint brushes [8], [18] and spray paint [19]. However, a notable gap in these approaches has been the absence of a dedicated clearing process, which is crucial for facilitating the inpainting process. The ability to clear and redraw areas enables the correction of errors and the refinement of details in the artwork. As a result, PICaSo stands out as the first system to address this by introducing efforts in the area of clearing processes.
Generative AI-Driven Drawing
Recent progress has showcased the potential of AI-based solutions in this area. In a study by [20], a generative adversarial network and a collaborative robotic arm worked with a 5-year-old child to create drawings on canvas. Moreover, various research works have introduced neuroadaptive learning algorithms for effective control in constrained nonlinear systems and robotic painting setups such as such as [12], [21], [22], [23], [24], [25], [26]. For instance, Tianying et al.[10] utilized GAN-based style transfer to transform facial images into simplified cartoon representations, while S. Nasrat [6] employed similar techniques to generate high-quality portrait drawings and Gao et al. [13] employed GAN-based style transfer to minimize the number of strokes needed for sketching artworks. Building upon these developments is CoFRIDA [27], which utilizes an adapted Instruct-Pix2Pix model to narrow down the semantic gap between simulated and real-world drawing allowing collaborative drawings between humans and robots. However, with these developments, there is still potential for enhancement in ensuring smooth collaboration and improving the organic nature of the drawing process. Our proposed system utilizes Natural Language Processing to simplify collaboration in drawings. Additionally, other methods lack scalability to facilitate multiple users working together on a shared canvas, which is a fundamental aspect of our system’s design.
Method
The System Architecture begins with user input through a simple interface as shown in Fig. , allowing for the input of both masks and text prompts. Following this, the generative drawing module generates a new image within the specified masked area. The waypoint generation module comes into play, creating drawing and clearing waypoints. Finally, the waypoint data is transmitted to the robotic arm for the drawing process on the canvas.
Generative Drawing Module
The primary aim of this module is to produce visuals for text-to-drawing and inpainting tasks, in a style that aligns well with the requirements of the waypoint generation algorithm.
Text-To-Drawing
Before inpainting, PICaSo needs to be capable of generating and drawing complete images from text. To achieve this, we employed SDXL1.0, a pre-trained model for text-to-image generation which builds on earlier Stable Diffusion models.
Inpainting
For the process of inpainting, we made use of SDXL-1.0-inpainting-0.1 - an enhanced inpainting model initialized with the weights from SDXL1.0 and designed to continue masked images effectively.
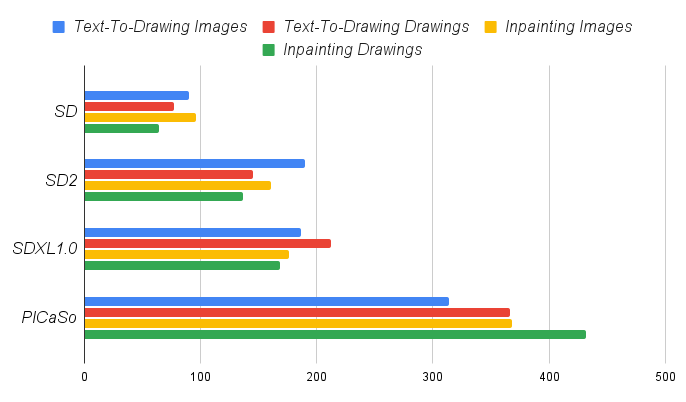
The waypoint generation required style involves excluding colored, bold lines, or shaded regions. To accomplish this, we curated a dataset comprising 40 cartoon images characterized by uniform thin black lines without color or shading – a stylistic prerequisite for the efficient operation of the waypoint algorithm. These images were obtained from cartoons in which colors and shadings were manually eliminated and textual annotations were added by hand. When working with pre-trained models, instead of training all network parameters totaling 6.6 billion in each model and to optimize resource usage and time efficiency, we employed LoRA [28] (Low Rank Adaptation) training technique by freezing base model and only training a subset of parameters with a network rank (dimension) of 128. The training process took four hours on a NVIDIA RTX 3090 graphic card. Additionally, we conducted comparative analysis among generated images produced from different models including our own in order evaluate their performance as shown in Fig. .
Waypoints Generation
We utilized the approach described by S. Nasrat et al. [4]. Initially, a morphological transformation is applied to simplify the sketch, smoothing pixel edges and removing isolated pixels. Subsequently, an efficient pixel-to-pixel algorithm extracts lines from the sketch, preserving important details while optimizing processing time. Line clustering reduces the number of lines by merging closely located ones to ensure precision and guide the robotic arm along the desired path information. In this study, a scaling algorithm was developed to convert pixel dimensions of a canvas image into metric sizes in Cartesian coordinates. The process involves converting each individual pixel into a meter-based Cartesian system using the pixel’s x and y coordinates shown in Eq. . This allows users to easily adapt to changes in pixel or physical canvas sizes according to their preferences. The vectors \(\boldsymbol{C}\) and \(\boldsymbol{P}\) represent the position on the canvas and the pixel position in the image, with \(\boldsymbol{C_0}\) and \(\boldsymbol{C_f}\) as start and end points on the canvas, while \(\boldsymbol{P_0}\) and \(\boldsymbol{P_f}\) correspond to start and end points of the image.
\[\boldsymbol{C} = \boldsymbol{C_{0}} + ((\boldsymbol{C_{f}} - \boldsymbol{C_{0}})/(\boldsymbol{P_{f}} - \boldsymbol{P_{0}})) * (\boldsymbol{P} - \boldsymbol{P_{0}}) \label{eq:scale}\]
Both drawing and clearing uses an interpolation movement approach through the generated waypoints showing visually appealing drawings. Utilizing the scaling algorithm with the interpolation movement made it was possible to generalize our system and be able to be used on different robotics arms as we tested on UR5 and RB-180 documented at Sec. .

Clearing Algorithm
During the clearing phase, each waypoint is revisited on the current canvas. Utilizing the user-defined mask, it precisely discerns which waypoints require erasure, facilitating the preparation for subsequent creative iterations. The process of tracing back waypoints falling within the mask is represented by Eq. , where \(W_{erase}\), \(W_{current}\), and \(M_{mask}\) respectively signify the set of waypoints to erase, the current waypoints on the canvas, and the user-defined mask area. The updated waypoints \(W_{updated}\) after performing the erase waypoints \(W_{erase}\) onto the canvas is represented by Eq. :
\[W_{erase} = \{\boldsymbol{C} | \boldsymbol{C} \in (W_{current} \cap M_{mask})\} \label{eq:waypoint_erase}\]
\[W_{updated} = W_{current} - W_{erase} \label{eq:waypoint_update}\]
Gripper Design
Enabling a seamless transition between the different functionalities was essential to this system, to achieve this we implemented a spring loaded multi-tool gripper mechanism. This gripper was designed to facilitate quick switches between the marker, eraser and camera modes offering a flexible and responsive approach to the process. Each tool in the gripper was configured with a 45-degree offset from the Tool Center Point (TCP) origin angle, allowing versatility and reach while maintaining precise control over the execution. Additionally, we included a spring mechanism in the marker tool to maintain consistent lines.
Experiments
Baselines Comparison
We examine how the fine-tuning procedure affects the generation of consistent waypoints in both the SDXL1.0 and SDXL1.0-inpainting models by contrasting them with alternative models in PICaSo’s Generative Drawing module, encompassing text-to-drawing and inpainting tasks.
Multiple User Inpainting
We test PICaSo’s inpainting scalability in multiple iterations of human-robot interactions, by allowing multiple participants to introduce new creative element onto the canvas, such as adding new components or modifying existing ones. and giving the freedom to change drawing canvas sizes to testing our scaling algorithm. Additionally we got participants satisfaction feedback while using the inpainting process.
Evaluation
Text-To-Drawing
We utilized CLIPScore [29] to gauge the similarity between images and prompts using pre-trained image-text encoders. Other benchmarks are incorporated such as BLIPScore [30], Aesthetics [31] and ImageReward [32] into our analysis. Additionally, we calculated the loss in the semantic meaning \(\triangle_{id}\) In Eq. . We measure the \(\triangle_{id}\) by calculating the absolute mean-error between the CLIPScore values of both the generated image \(\boldsymbol{I_{img}}\) and its corresponding drawing \(\boldsymbol{I_{draw}}\).. Due to potential bias related to CLIPScore, human evaluation was also conducted.
\[\triangle_{id} = 1/n \sum_{i=1}^{n} |CLIP(\boldsymbol{I_{draw_i}}) - CLIP(\boldsymbol{I_{img_i}})| \label{eq:clip_difference}\] difference
Inpainting
We evaluated the data collected from the multi-user inpainting sessions we conducted, evaluation is done using CLIPScore and other benchmarks between inpainting models.
Results
Text-To-Drawing
In order to assess the effectiveness of our refined approach in the text-to-drawings method, we conducted a comparison of image and drawing outcomes between runwayML(SD)[33], stable-diffusion-2(SD2)[34] and SDXL1.0 as base models, including our fine-tuned model. Our investigation focused on examining the impact of our fine-tuned model’s ability in text-to-drawing transformation. We produced 50 pairs of images and drawings pairs per model while maintaining consistent settings for prompt, size, and generation seed, where some of the results are shown in Fig . CLIPScore, BLIPScore, Aesthetics and ImageReward measures are reported in Table . PICaSo (fine-tuned) demonstrates the highest scores followed by the SDXL1.0 a base model, this was expected given that our fine-tuned model is based on SDXL1.0. in terms of the absolute mean-error (\(\triangle_{id}\)) between images and drawings CLIPScore, our fine-tuned model outperforms the baselines highlighting the efficiency in producing the required style for efficient waypoint generation resulting in visually appealing drawings.
We adequately evaluate the dataset through human evaluation, as utilizing AI-based evaluation may lead to biased results, a survey was carried out as depicted in Fig. . 20 distinct participants were involved and presented with a language description along with four images generated by different base models as well as our fine-tuned model, resulting in a total of 100 drawing-image generated pairs. Participants were instructed to select the most aesthetically pleasing image and drawing based on the textual description provided. For both images and drawings, the majority favored the output of our fine-tuned model for its simple yet descriptive style. The particular preference for our drawings emphasizes PICaSo’s effectiveness in translating the refined style onto the canvas while maintaining visually appealing results.


Inpainting
Similarly to the text-to-drawing benchmark, we conducted a comparison and survey to evaluate the inpainting dataset curated from several multi-user inpainting sessions. In this comparison we use stable-diffusion-inpainting(SD), stable-diffusion-2-inpainting(SD2), and SDXL1.0-inpainting as baseline models along with our fine-tuned inpainting model. Our dataset consists of 50 image-drawing pairs generated from each model while maintaining consistent settings and input masks. Some examples of the dataset are shown in Fig. . The inpainting dataset consists of different tasks involving removing objects, redrawing character pose and drawing objects from an empty background. Table reports CLIPScore, BLIPScore, Aesthetics, ImageReward and absolute mean-error (\(\triangle_{id}\)) measures. PICaSo (fine-tuned) out performs other models. On the CLIPScore metric the base model SDXL1.0-inpainting ranks second after our model, which aligns with expectations as our fine-tuned model is built upon it. The decrease in absolute mean error (\(\triangle_{id}\)) demonstrates the quality of image translation onto the canvas using our trained style. In addition, we carried out a survey using the inpainting dataset under the same conditions as the text-to-drawing survey. The results of this survey are depicted in Fig..
Inpainting Scalability
To evaluate the performance and collaborative scalability of the PICaSo system’s inpainting process in multiple iterations of human-robot interactions, several multi-user inpainting sessions were conducted, wherein each participant contributed new creative element to the canvas, Examples of these sessions are depicted in Fig. . Notably, one session involved 10 participants, as detailed in Table . Within this session, a participant initiated the process by adding a character which was subsequently edited by others through the addition of various features such as glasses, a suit, a smile, a full body, and the transformation of a balloon into an umbrella etc... . This collective effort resulted in a single artwork collaboratively crafted by 10 individuals, utilizing our system to articulate their ideas into a physical canvas through Natural Language. Based on the participants feedback PICaSo scores a 86.7% satisfaction rate in using the system in collaborative inpainting.
Discussion
The exploration of new artistic styles and techniques stands as a promising avenue for the advancement of the PICaSo system. Despite the current emphasis on traditional artistic forms, numerous unexplored avenues beckon for exploration. For instance, the mimicking of an artist style or incorporating drawing techniques as minimalist one-line drawing, which offer rich potential for experimentation and innovation within the PICaSo framework. Leveraging the capability to merge different LoRA adapters further expands the system’s capacity to generate diverse artistic outputs by blending various LoRA image styles.
Furthermore, advancements in text-to-image models hold significant promise for enhancing the capabilities of the PICaSo system. Future iterations of these models may facilitate a more nuanced understanding of images, enabling the system to interpret and render complex visual concepts with greater fidelity. This could greatly enrich the system’s ability to translate intricate textual descriptions into dynamic and multifaceted artistic compositions on canvas. As such, ongoing research into text-to-image models presents an exciting opportunity for the continued evolution and enhancement of the PICaSo system’s creative capabilities.
Conclusion
The PICaSo system is a flexible platform that allows for the exploration and development of the combination of artificial intelligence, human creativity, and robotics. Our research into fine-tuning and tool selection has shown how adaptable and scalable the system is in the process of robotics inpainting on physical canvas. Additionally, we have implemented a clearing process to enable multi-user editing on a single canvas using natural language input. Pre-trained models are unable to produce the desired style according to the waypoint algorithm. However, our fine-tuned models provides an effective style in terms of both time and quality, as confirmed by both image-text encoders and human evaluation. Additionally, the innovative method for clearing canvas sections enabled multiple users to engage in inpainting sessions, with one notable session involving 10 participants working together to combine their distinct ideas onto a single canvas. In future work, we aim to explore the potential of integrating different painting styles into our robotic system and introducing colors into the system, allowing users to articulate more complex ideas onto the canvas.
참고문헌
*This project was funded by Police-Lab 2.0 Program(www.kipot.or.kr) funded by the Ministry of Science and ICT(MSIT, Korea) & Korean National Police Agency(KNPA, Korea) (No. 082021D48000000) and Korea Institute for Advancement of Technology(KIAT) grant funded by the Korea Government(MOTIE)(P0008473, HRD Program for Industrial Innovation)↩︎
Authors are with Faculty of Electrical Engineering, Pusan National University, Busan, South Korea
seungjoon.yi@ pusan.ac.kr↩︎